歡迎來到莉芳的科學小玩意,一起來做文字辨識吧!
最近在精讚部落出現了一個小活動,「不正常人類人腦智慧研究所,分析你的文字辨識率。」就是右邊這個隨著文章一直反覆出現的區塊。
「你會不會看錯這些字?下面這些字哪些你覺得很像?」這是什麼玩意呢?
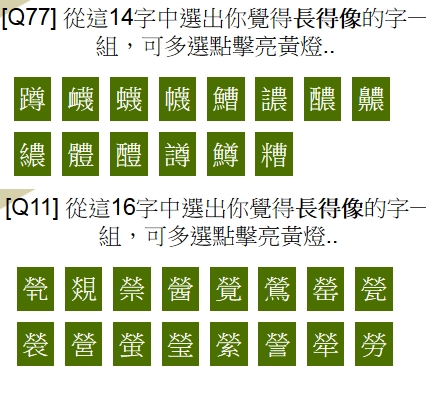
「中國字的複雜常讓外國人怯步,在外國人眼中的中國字是一團看起來很好看的『圖像』。就連中國人或使用中文字很久的人,看錯字寫錯字也是常有。」究竟這些容易被看錯的字有哪些共通點?外國人與我們辨識程度一樣嗎?哪些部首或字根組合最容易看錯?
|
形近字是指幾個字形結構相近的字。我簡單整理分析如下:
|
|

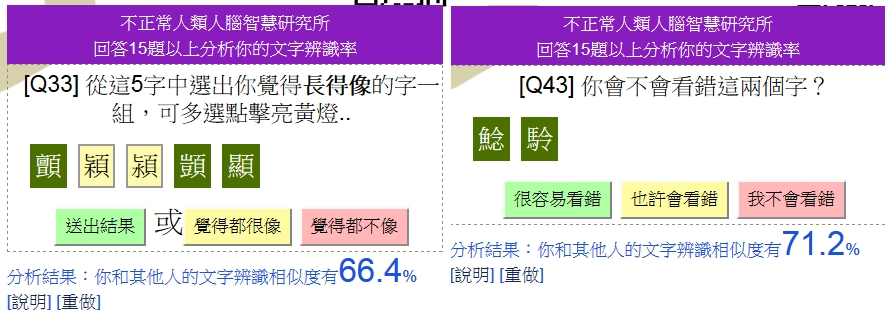
測驗採用「人腦智慧中文字辨視系統」引擎,讓我們的選擇和別人的選擇做比較,測驗看自己的中文字辨識能力和別人有沒有相同。一開始我還會在意辨識度,也會去想~是不是有人會故意找碴來亂,總是唱反調呢?後來~不自覺地只要有機會有時間,就點個幾題來做做。這系統可怕之處就是在於你會忍不住一直做下去。
我家六歲小兒柚子看到我在操作之後,非常感興趣,新的題目不斷跳出。他問我為什麼不把題目做完。這小子想把題目做完!
「題目做得完嗎?嘿嘿。」開了iPad給他操作。
柚子很努力~~不時報告進度。「我做了125題,比您多~對不對?」他認為是在跟我比賽。
他還很驚訝地發現上頭有分數。那是文字辨識率,不是分數啦!(詳見精讚說明。)
「還要再做嗎?」問這小子。
「我要做到1000題為止!」他已經做到215題。
「做到250題就好,不要一直做了。」
「又沒關係~為什麼不能一直做?」唉~ 明明是要教小孩子有耐心,怎麼我會要他不要一直操作呢?做太久了,總是怕他傷眼睛。最後柚子”只”做了317題,我趕緊關上iPad知道這會忍不住做下去。
「那一共有幾題?題目會重覆嗎?」說真的~我也不知道。
柚子眼光和我有很多不同,他一看就覺得像的字,我覺得差很多。我覺得很容易看錯的,他則會告訴我~明明就是哪裡不一樣!
我也很好奇,初學中文的外國人,剛在識字的小孩~做出的結果有什麼不同?這需要足夠多的樣本數才能進一步做分析。
這個系統有趣的地方在於題目是自動演進的,而且作答的人次越多,準確度就會越來越高,歡迎大家不同時間來作看看。版面的文章也因為這個活動,前面幾段文字圖片版面稍有跑掉,還請見諒。