需要某網站資料抓回來統計,結果當然沒我想的那麼簡單, 程式跑一跑就撈回來
光這裡就卡好久, 後來觀察cookie 從 cf_clearance 找到這篇文章
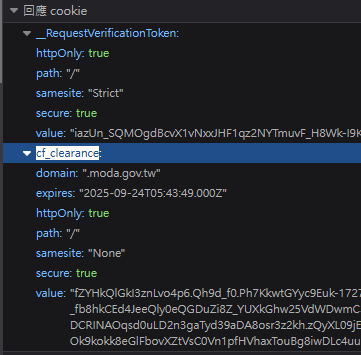
目前只能做到半自動, 使用firefox 建立session後
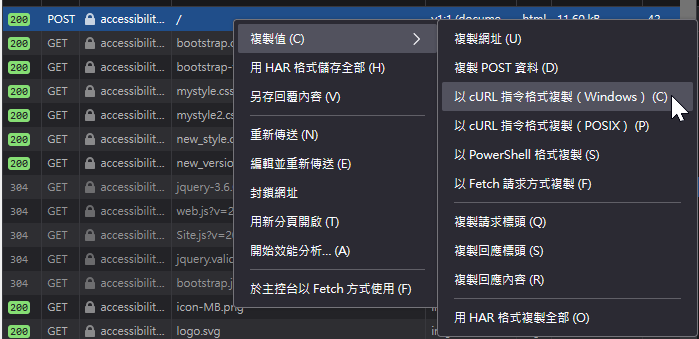
如圖複製cURL指令,產生bat檔 ,再執行bat,將3x 頁面抓回來解析
import re
#delete tmp files
for file in os.listdir('./tmp/'):
if file.endswith(".html"):
os.remove('./tmp/'+file)
maxPage=int(input("how many pages:"))
# 產生一run.bat, 再執行run.bat檔
inputstr = input("paste here:")
inputstr = inputstr.replace("AgencyDepartment=^%^E4^%^B8^%^AD^%^E5^%^B8^%^82", "AgencyDepartment=中市")
inputstr = inputstr.replace("--compressed","")
inputstr = inputstr.replace("-H \"Accept-Encoding: gzip, deflate, br, zstd\"","")
runFile = open("run.bat","w")
#取關鍵字Index/\d 截斷, 再重新組成curl 需要的網址
for i in range(1,maxPage+1):
fileName = str(i)+".html"
command = re.split(r'Index\/\d', inputstr)[0] + "Index/" + str(i) + re.split(r'Index\/\d', inputstr)[1] + " -o ./tmp/" + fileName
print(command)
runFile.write(command)
runFile.write("\n")
runFile.write("timeout 2")
runFile.write("\n")
runFile.close()
print("done")