
自動目錄
我好奇分析了精讚最近的180萬次訪客記錄。
資料是自有的,並非來自 google analytics之類的記錄,同時也有過濾掉三天內重複的來源。
訪客來源
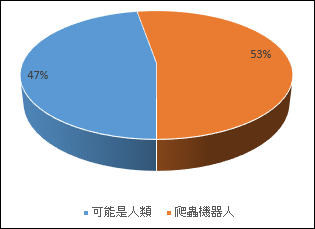
爬蟲或機器人比正常人來得多,從數據分析可看出53%是屬於爬蟲或機器人,可能是人類的比例約為47%。
有些擬人類的爬蟲或機器人可能混進來,因此實際比例可能人類更少。
爬蟲的來源
我分析出的爬蟲大約有50-100種之多(事實上可能更多),某些偶爾來幾次的爬蟲就直接歸納到其它項目中,分析出前幾大爬蟲數量和所占爬蟲的比例
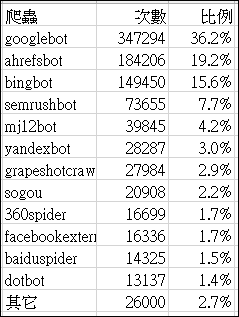
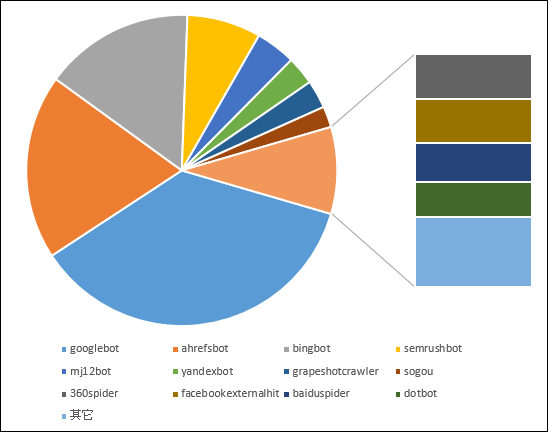
前幾大中排第一名的是 google的爬蟲。
第二名的 ahrefsbot https://ahrefs.com/robot ;;; 不知是什麼來頭的公司
第三名是微軟的 bing
第四名是semrush https://www.semrush.com/bot/
此四大爬蟲就約占了爬蟲來源的 79%,也就是說這四隻是超級大爬蟲。
爬蟲的來訪對網站的曝光是好事,但會吃掉不少頻寬也是壞事。
還好網站當初在建置的時候我就有考慮過,只要是被判定是爬蟲的來源,在「正被關注」的地方會標注一個大寫的B,表示我知道你的來訪,但是不會列入點擊次數。
裝置的來源
藉由 google的分析這近12個月的資料,可以知道本站有約 31.6+1.9=33.5(%)的使用者是來自於行動裝置
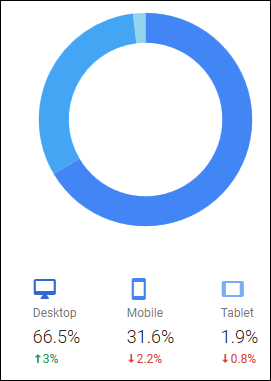
以上是簡單的分析資料,大概知道就好。By Alexa 的分析 https://www.alexa.com/siteinfo/sfs.tw
到目前為止本站的排名約
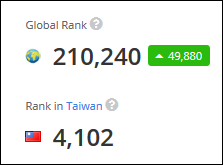
參考參考。
END
