
自動目錄
一般人查姓名音譯時,一般會去找外交部的網頁[1],畢竟這是官方網頁,無可厚非。
網路上有幾個存活比較久的姓名音譯網站,排名只似乎說明了一切。
但現在要介紹的這個網站,我相信遠遠的比上面這些都要來得強,贏好幾條街。
理由一 不必選擇
為什麼我這麼說,首先,我不喜歡作選擇,大部分的網站很貼心的把所有的讀音結果列出來,例如試著打入「區長和」這三個字,區有2個讀音、長有3個讀音、和有6個讀音,總共有2*3*6=36種組合。
要我選出我認為最適當的,我覺得根本不必要。
因為我覺得根本不需要選擇。
這個名字,絕大部分的人會讀成 ㄡ ㄔㄤˊ ㄏㄜˊ ,理由是區這個字作為姓,一般是唸成ㄡ;長的慣用音是長度的長ㄔㄤˊ;和的慣用音是和平的和ㄏㄜˊ
此系統只會顯示一筆最佳結果,不會使用罕見的讀音作為姓名的讀音。
這是最棒的地方。
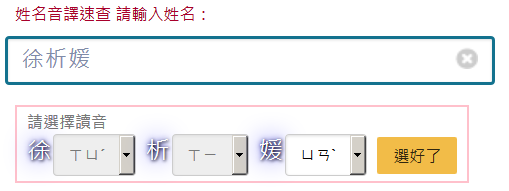
但是如果我認為我對我的姓名讀音有偏好,想要選擇呢?系統有提供選讀音的功能。
對於一字一音還要不要選?在系統中可以看到,一字一音的字選項是灰色底,你根本不必選。
像我在寫程式時,常常會因為偷懶,很多細微的地方就算了(反正使用者也無感),這裡不得不誇這個網站做得非常的精緻,
你就算是開起選讀音的功能,不需要選的字,系統是不會讓你有多餘的操作,你只要專注在你需要選的字上。
但如果姓和名所有的字都是一字一音不必選的話,系統會不會出現選字?
這又得再誇讚這個網站第二次,因為他就根本不會出現選擇項,直接就跳結果給你看。
因為我寫程式我知道,如果都讓選,程式比較好寫,反正都跳選擇,要判斷該不該選,像這種處理就很細心,寫程式很麻煩,結果很簡單。
理由二 雙複姓自動判讀
很多網站是沒辦法分辨雙複姓,反正我就全部列給你看,你自己挑。
這種方式我也認為是很草率的,力扣網在作地址判斷郵遞區號的功能非常的強,我相信在做姓名音譯不可能會這麼粗糙。
大家耳熟能詳的雙複姓我覺得系統應該要能自動判讀,沒道理還要人家選擇或全部列出,例如歐陽修。

他出來的結果,只有一種。
不得不佩服,和這網站的精神很像:超高精準度。
如果使用者真的姓「歐」名「陽修」那系統不就死了嗎?
當然不可能,你可以打開系統的姓名分隔設定,只要輸入時「歐」和「陽」之間多一個空白,系統就會自動判斷

一開始我會擔心如果空白多了,或是最前後有空白時會不不分析錯誤,其實你擔心是多餘的。像下例不知加了多少空白,系統還是很正確的判斷。

你如果又擔心雖然設定「以空白分隔姓和名」,但我沒分隔系統會怎樣?和你說,結果還是很正確。
理由三 雙複姓讀音是正確
網路上的姓名音譯系統有個盲點,就是雙複姓時他們會以字的單音來讀,而不是雙複姓該有的正確讀音,例如常見的「令狐沖」

他把令翻成二聲「ㄌㄧㄥˊ」,而不是大家常聽到的四聲命令的「令」,那如果輸入姓「令」名「狐沖」呢?我很好奇。

再找一個特別的例子,姓「万俟」的。這兩個字要念成「莫其」。
其化很多系統會翻成「萬以」,更糟的事,還有系統「自動」翻成「萬俟」的,把人家改祖先啊。

更令我吃驚的還不止這樣,這也是我會推薦的主因,因為實在太精緻了,精緻在細微的地方,不得不誇讚。例如有人的名中會出現「一」,
這個字一般而言是念一聲,但是如果你以為系統都會判斷一聲的話,你就太小看它了,我不知道其他的結果是否如此,但這點讓我吃驚!




難怪系統可以把選字的功能收起來,真的很少需要選字音。
理由四 大量分析功能
能提供大量分析,自動分隔等等功能。
不過大量的功能是要收費的,但可申請測試試用。
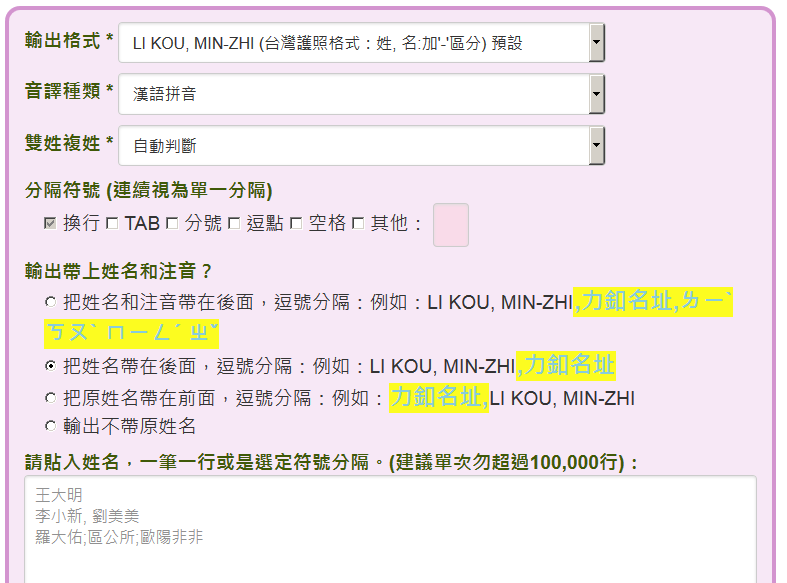
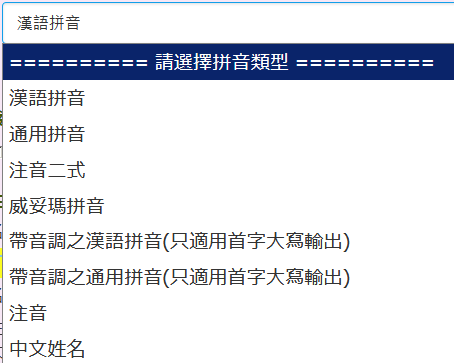
大量分析功能中有一個特別的地方,就是他的輸出格式可選的有十幾種

姓和名之間分隔設定可以使用空白、逗點或自動三種,比網頁查詢的多一種。
此外音譯輸出比起網頁查詢能複選,這裡一次只能輸出一種這是限制
理由五 收集的字多
中國字有好幾萬,會用做姓名的字最怕出現找不到的問題,還好測試後發現這個網站的字收錄的字非常的多:
這是測試打得出來的字,我想一定沒問題,因為我的輸入法打得出來

接下來測試打不出來的字「㯤䨇㗊」,這些字存在於unicode中,我好不容易找了幾個測試

再測試日本漢字「躾徳産阪」,這些漢字長得都和我們用的有一點不一樣,我想這個應該不行,結果…

誰知道這些讀音對不對?至少不會留個空白給我。
最後拿出殺手鐗了,這些字都只有一個讀音的方言字。「甮覅嗲」

上面那些字你們去測別的系統,但目前為止都還不能完全音譯的,這裡沒問題。
所以推薦這樣。
參考資料
[1] https://www.boca.gov.tw/sp-natr-singleform-1.html
