
自動目錄
常常看到有些文字會用 0x12AB 或是 0x0123AB、U+4AE0、Ӓ 這種形式表示,這種寫法到底是什麼意思?和我們常用的文字之間有什麼關係?
常聽到的 unicode, utf8, ascii 又是什麼?utf8和unicode之間的關係及如何轉換?藉由此文整理並徹底了解。
Unicode
unicode 簡介
計算機起源於美國,上個世紀,他們制定了一套字符編碼規則,稱爲 ASCII 編碼。
ASCII 編碼一共定義了 128 個字符,裡面有英文大小寫數字、標點符號及一些控制用符號,這些字符組成的集合就叫做 ASCII 字符集。
隨着計算機的普及,在不同的地區和國家又出現了很多字符編碼,比如: 大陸的 GB2312、港臺的 BIG5, 日本的 Shift JIS 等等。[1]
但是由於字符編碼不同,文字在不同國家之間經常需要轉換,否則會出現亂碼,網際網路的出現這種情況越來越嚴重需要解決。於是1990開始就有許多機構致力於統一不同的文字編碼,於是 Unicode 就出現了,歷經幾十年的發展,成為現在看到的版本。
簡單來說,unicode 就是把現有的文字符號等加以編碼收集起來,有點類似一本超大字典,所以unicode 也可稱為通用字元集ucs(英語:Universal Character Set, UCS)[3]。
unicode的分組
目前的unicode字符分成17組,從U+0000 至 U+10FFFF,每組稱為編碼平面(Code Plane),每平面擁有65536個編碼點。
其中 U+0000 ~ U+FFFF 稱為基本多語言平面(Basic Multilingual Plane,簡記為BMP),也叫做平面0。平面0包含了世界上多種文字。
其餘劃入16個輔助平面(Supplementary Plane),編碼點範圍U+10000 ~ U+10FFFF。
其中平面0的中文字群範圍:
4E00-9FBF:CJK 統一表意符號(CJK Unified Ideographs) 包含漢字
總共有40895-19968= 20927個漢字
其餘分群請看[6]
unicode 表示方法
在表示一個Unicode的字元時,通常會用「U+」或小寫的「u+」然後緊接著多組十六進位的數字來表示這一個字元。例如
U+50
U+3105
u+0123AB
程式語言有時會用 0x代替 U+,例如
0x3105
網頁上的表示方法
如果想在網頁上呈現unicode,把 'U+' 替換成 '&#',把十六進位的編碼換成十進位,最後在字元的結束加上分號即可,例如顯示注音符號的ㄅ,查碼發現編碼是u+3105,
要把3105換成10進位,即12549,那在網頁上打上
ㄅ
就會出來注音符號的ㄅ。
PHP上顯示unicode[4]
print 0x3105; //12549
json_decode('"\u3105"'); //ㄅ
查詢unicode
那要怎麼知道文字的unicode編碼?當然如果可以直接打出來的字不必理會他的編碼,但有些字是以現有的輸入法打不出來的,這時就可以使用查表的方法
可以參考以下網站(2022.3):
unicode有分類清單 https://jicheng.tw/hanzi/unicode?s=9F9C&e=9F9C&font= ;;; (推薦[6])
全字庫 https://www.cns11643.gov.tw/searchQ.jsp?ID=0
unicode清單有轉10進位 https://www.ifreesite.com/unicode/character.htm
UTF8
unicode是字元集,要實現的話還是得靠編碼系統,其中有名的有 utf8, utf16, ucs2, ucs4等等。
根據w3tech[5]的研究,到了2022.3,utf8已占了網頁中全部編碼系統的 98%。其餘編碼雖然仍存在諸多系統中,但使用數量已漸漸示微。
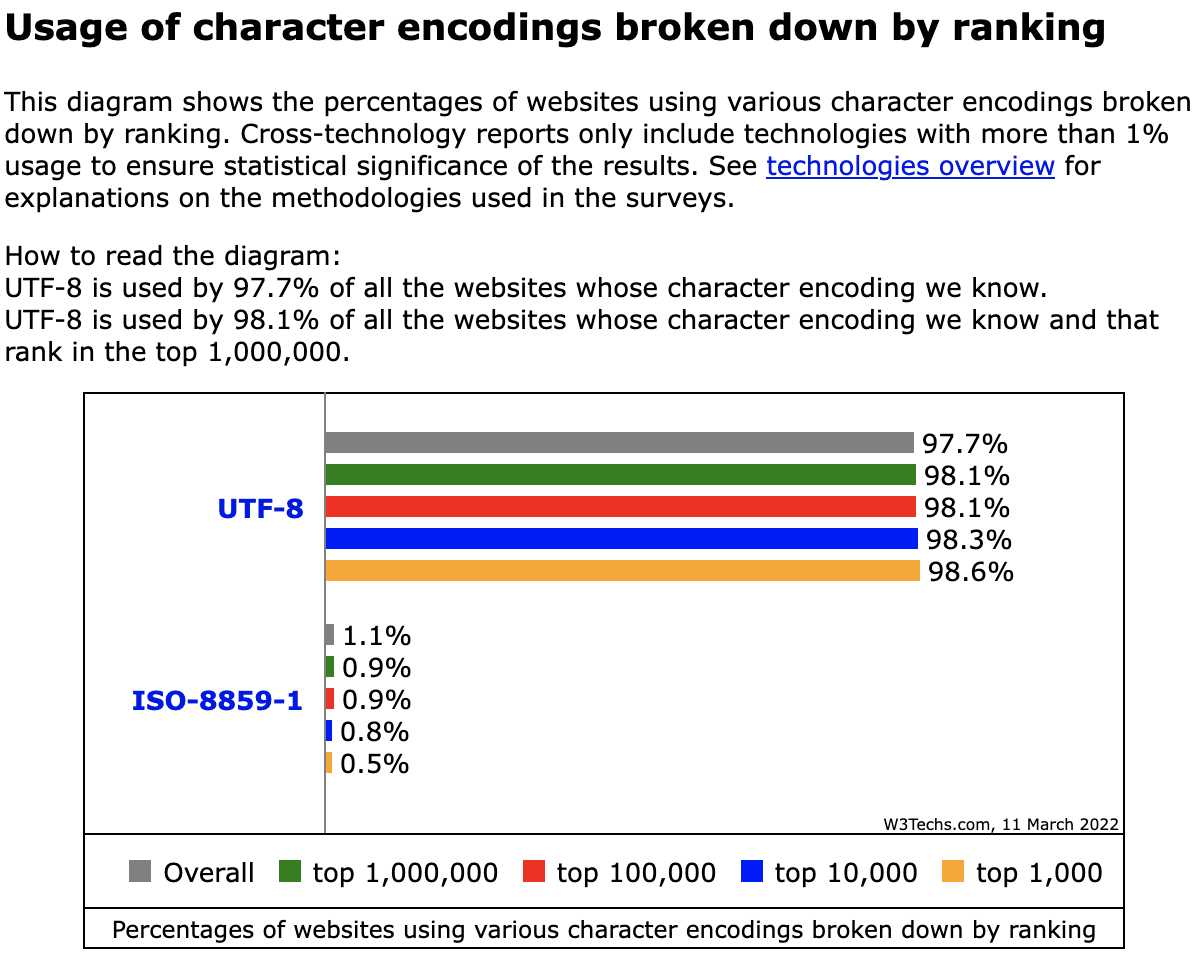
UTF8的編碼方式
UTF-8是一種非固定長度字節編碼方式。最長可達6個bytes(以下稱為字節)組成一個字,最短只需1個byte。這樣的好處是他相容於ascII的編碼方式。
以下是 UTF-8 的編碼原則(2進位)。
1字節 0xxxxxxx
2字節 110xxxxx 10xxxxxx
3字節 1110xxxx 10xxxxxx 10xxxxxx
4字節 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字節 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字節 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
舉例如下,粉底代表定義的指定位元:
A=> 65 => 01000001 <== 等同於ASCII
и=> 208 184 => 11010000 10111000
錢=>233 140 162 => 11101001 10001100 10100011
ね=>227 129 173 => 11100011 10000001 10101101
一隻豬(請看下圖)=>240,147,131,159 =>11110000 10010011 10000011 10011111
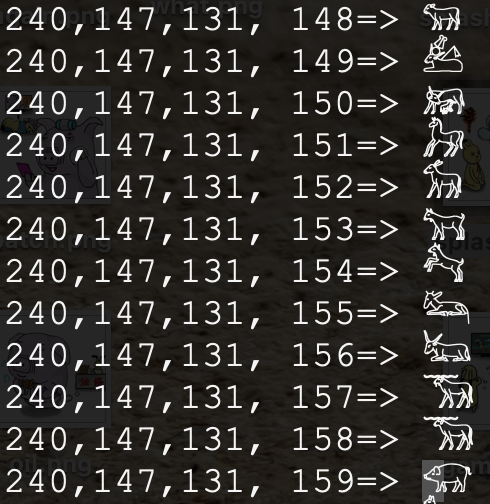
四個字節的字有些電腦無法正確顯示,請參考上圖。
簡單的判斷方法,第一個字節2進位有幾個1開頭就是幾個字節的UTF8字。
各字節組擁有的字數
1字節 0xxxxxxx => 2^7= 128個
2字節 110xxxxx 10xxxxxx => 2^(5+6)= 2048
3字節 1110xxxx 10xxxxxx 10xxxxxx => 2^(4+6+6)= 65536
4字節 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx => 2^(3+6+6+6)=2097152
5字節 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx => 67108864
6字節 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx =>2147483648
基本上用3個字節就足以涵蓋67000個字、4個字節就足以涵蓋215萬個字,五個字節以上的字目前沒有。
UTF8和unicode 之間的轉換
UTF8是變動字節長,而unicode 是固定字節,這兩者之間如何轉換?
unicode轉成 UTF8
Unicode 的字節編碼對照UTF8的編碼方式
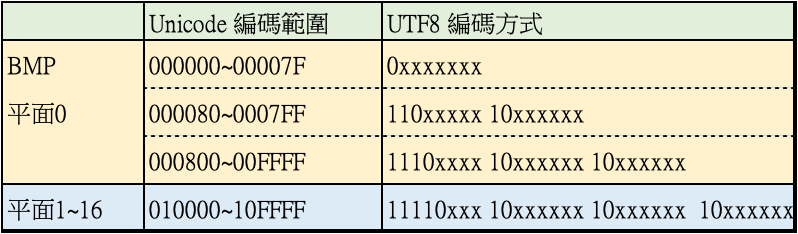
直接用範例作說明,例如中文字的「錢」unicode 是 U+9322
1. 因為是9322,屬於平面0 000800~00FFFF這個範圍,也就是三字碼UTF8
2. 9322 => 93 22 (16進位)=> 10010011 00100010 (2進位) => 16個位元拆成 4, 6, 6 分組
=> 10010011 00100010
3. 將分成的3組代換掉 UTF8 的xxxx..
11101001 10001100 10100010 => 233 140 162 (10進位)
利用PHP來驗證
結果
錢
UTF8轉成unicode
由UTF8 轉成unicode 只要倒過來運算即可。
以剛才的錢字為例:
1. 取得UTF8 編碼 233 140 162
2. 轉成二進位 11101001 10001100 10100010
3. 把顏色的部分組合=> 10010011 00100010
4. 8個位元一組轉成16進位=>93 22
5. U+9322完成
參考資料
[1] https://www.readfog.com/a/1638084002220969984
[2] https://zh.wikipedia.org/wiki/Unicode
[3] https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%AD%97%E7%AC%A6%E9%9B%86
[4] https://stackoverflow.com/questions/17539412/print-unicode-characters-php
[5] https://w3techs.com/technologies/cross/character_encoding/ranking
[6] https://jicheng.tw/hanzi/unicode?s=9F9C&e=9F9C&font=
